Understanding Machine Learning
Let’s start from scratch.
Firstly, I’ll talk about what machine learning really is and what are the various machine learning tasks.
Making a machine learn is the meaning we usually infer from the term Machine learning, which is correct to a certain extent. Well, here’s a well-known definition:
Machine learning is a type of artificial intelligence (AI) that provides computers with the ability to learn without being explicitly programmed.
Another recent definition goes something like this:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
You probably don’t realize but machine learning is used in a wide variety of things and is all around you. For instance, snapchat’s cool filters, Youtube’s recommended videos, the spam filter in your emails and the list goes on. Here are some really awesome applications of machine learning:
- Extrapolating the scene of a painting to see what the full scenery might have looked like.
- AutoDraw: This app tries to guess what your trying to draw and you can then use its suggestions to create the perfect art.
- Wavenet: Generating audio waveforms from text to speech. Here if we have sample of someone’s voice, we can generate speech from a given text using that voice.
Now that you’ve got an idea what machine learning essentially is, we’ll try to understand what are the different machine learning tasks that exist.
Machine learning tasks can be broadly classified into three categories:
- Supervised learning: The machine is given an input and the desired output, the task of the machine is to define a rule to map the input to the desired output. This general rule can then be used to predict an output for an unseen input. For example: Predicting whether a breast cancer tumor is malignant or benign given a set of cell nucleus properties.
- Unsupervised learning: The machine is given an input but without a desired output. So the task of the machine is to figure out the structure and patterns from the input to predict the output. For example: Predicting variations in different types of customers a company deals with. This would help the company to structure their services in a better way and deal with different customer segments effectively.
- Reinforcement Learning: The machine has to perform a specific task in a dynamic environment, where it is provided feedback in form of rewards and punishments as it navigates through the problem space.
While supervised learning is about make sense of the environment based on historical data, reinforcement learning is pretty different.
For instance, trying to drive a car on a road based on previous week’s traffic patterns, which is clearly ineffective. Reinforcement learning on the other hand is all about reward, you get points for actions like staying in your lane, driving under the speed limit, stopping at the red light etc. and you can lose points too for dangerous things like speeding. Here, the objective to get maximum number of points given the current state, i.e. the traffic around you.
All of the above fields are huge, and hence, explaining each one of them in detail is out of the scope of this article. Therefore, in this article i’ll be talking specifically about supervised learning.
Understanding Supervised Learning
Let’s understand more about supervised learning.
Before I begin explaining about supervised learning in more detail, I’ll introduce you to a famous dataset in supervised learning - the Iris dataset. The iris dataset consists of five columns, namely: sepal length, sepal width, petal length, petal width and species (which is a categorical variable with three possible values: setosa, virginica, versicolor).
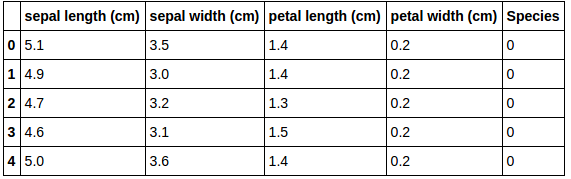
First Five rows of the Iris dataset
A particular row describes all the features of a specific flower and a particular column describes about a specific feature of all the flowers. Features are also called the independent variables, and the target variable (which is to be predicted) is also called the dependant variable (species).
So, in supervised learning for training we use such a dataset which consists of both features and the target variable and then use the rule (derived after training) to predict labels of unlabelled data. Training is done with the objective to minimize error, which quantitatively describes the incorrect predictions the model is making.
Supervised learning can be broadly divided into two major categories, aim of both the categories is to derive a rule to predict the dependent variable given the features (or independent variables):
- Classification: The target variable consists of finite discrete values, where the values can be numerical or categorical. For example: in the iris dataset, the target variable is categorical and it can take only three values, i.e. versicolor, setosa and virginica. Examples of some classification algorithms are logistic regression, decision trees, naive bayes .
- Regression: The target variable consists of continuous values, which essentially is always numerical. The boston house prices dataset (only the first five instances are shown) consists of a continuous target variable “Price” (note that here the target variable can take any value over a continuous range, hence, the target variable is of continuous nature).
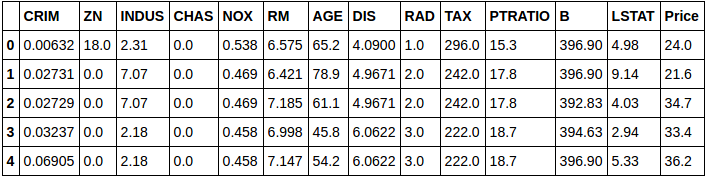
First Five rows of the Boston dataset
Some regression algorithms are linear regression,polynomial regression and lasso regression.
I will be discussing about these algorithms in upcoming articles. Till then keep calm and enjoy machine learning.
Some awesome resources:
- Coursera’s Introduction to machine learning taught by Andrew Ng
- Datacamp’s courses on data science in R and python
- Introduction to Machine Learning with Python: A Guide for Data Scientists by Andreas C. Müller and Sarah Guido
- For a list of more machine learning tutorials check out this cool Github repository.